“The king is dead”—Claude 3 surpasses GPT-4 on Chatbot Arena for the first time

The battle for AI vibes —
Anthropic’s Claude 3 is first to unseat GPT-4 since launch of Chatbot Arena in May ’23.

On Tuesday, Anthropic’s Claude 3 Opus large language model (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the first time on Chatbot Arena, a popular crowdsourced leaderboard used by AI researchers to gauge the relative capabilities of AI language models. “The king is dead,” tweeted software developer Nick Dobos in a post comparing GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since the first inclusion of GPT-4 in Chatbot Arena around May 10, 2023 (the leaderboard launched May 3 of that year), variations of GPT-4 have consistently been on the top of the chart until now, so its defeat in the Arena is a notable moment in the relatively short history of AI language models. One of Anthropic’s smaller models, Haiku, has also been turning heads with its performance on the leaderboard.
“For the first time, the best available models—Opus for advanced tasks, Haiku for cost and efficiency—are from a vendor that isn’t OpenAI,” independent AI researcher Simon Willison told Ars Technica. “That’s reassuring—we all benefit from a diversity of top vendors in this space. But GPT-4 is over a year old at this point, and it took that year for anyone else to catch up.”
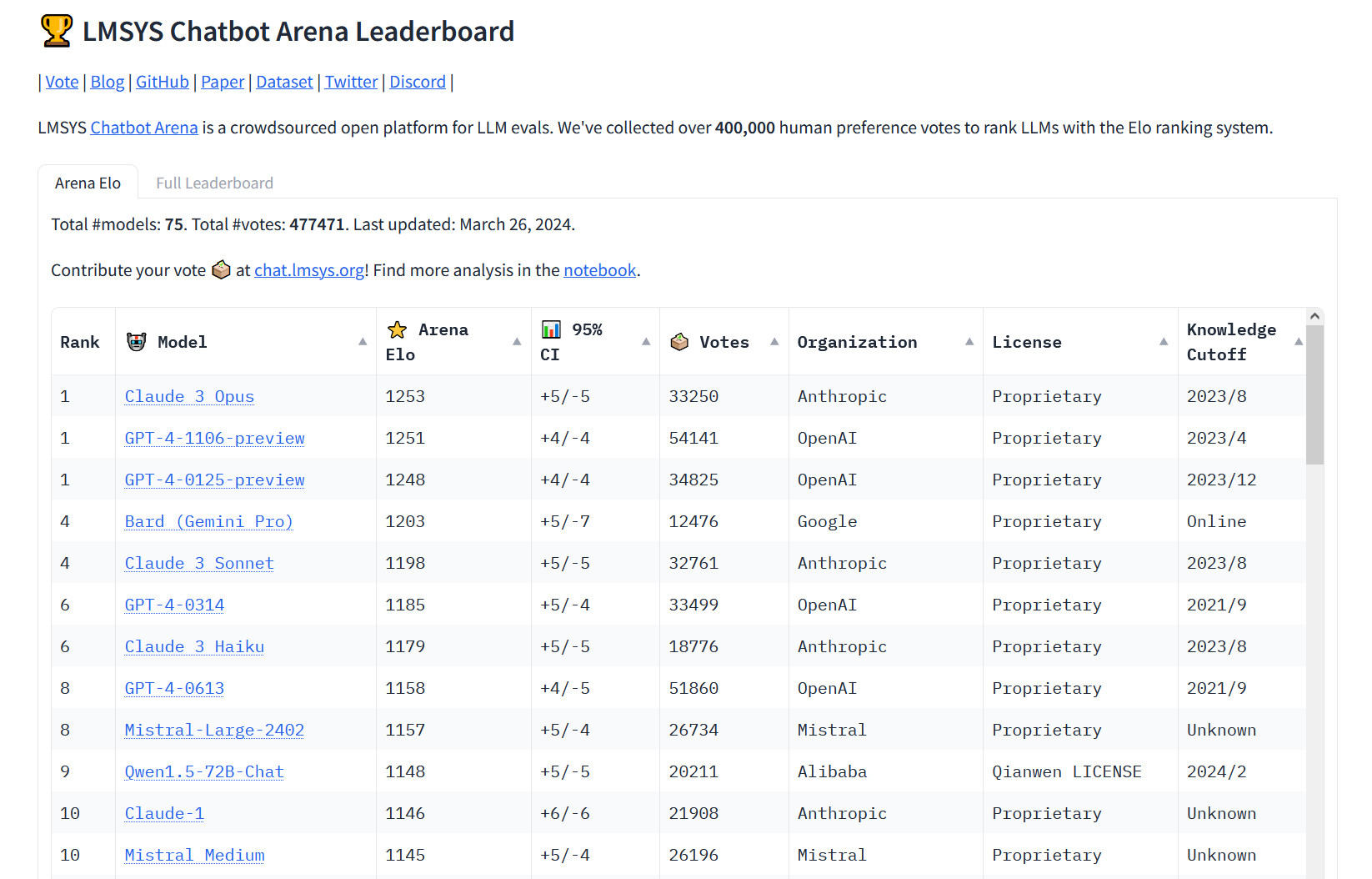
Enlarge / A screenshot of the LMSYS Chatbot Arena leaderboard showing Claude 3 Opus in the lead against GPT-4 Turbo, updated March 26, 2024.
Benj Edwards
Chatbot Arena is run by Large Model Systems Organization (LMSYS ORG), a research organization dedicated to open models that operates as a collaboration between students and faculty at University of California, Berkeley, UC San Diego, and Carnegie Mellon University.
We profiled how the site works in December, but in brief, Chatbot Arena presents a user visiting the website with a chat input box and two windows showing output from two unlabeled LLMs. The user’s task it to rate which output is better based on any criteria the user deems most fit. Through thousands of these subjective comparisons, Chatbot Arena calculates the “best” models in aggregate and populates the leaderboard, updating it over time.
Chatbot Arena is important because researchers and users alike often find frustration in trying to measure the performance of AI chatbots, whose wildly varying outputs are difficult to quantify. In fact, we wrote about how notoriously difficult it is to objectively benchmark LLMs in our news piece about the launch of Claude 3. For that story, Willison emphasized the important role of “vibes,” or subjective feelings, in determining the quality of a LLM. “Yet another case of ‘vibes’ as a key concept in modern AI,” he said.
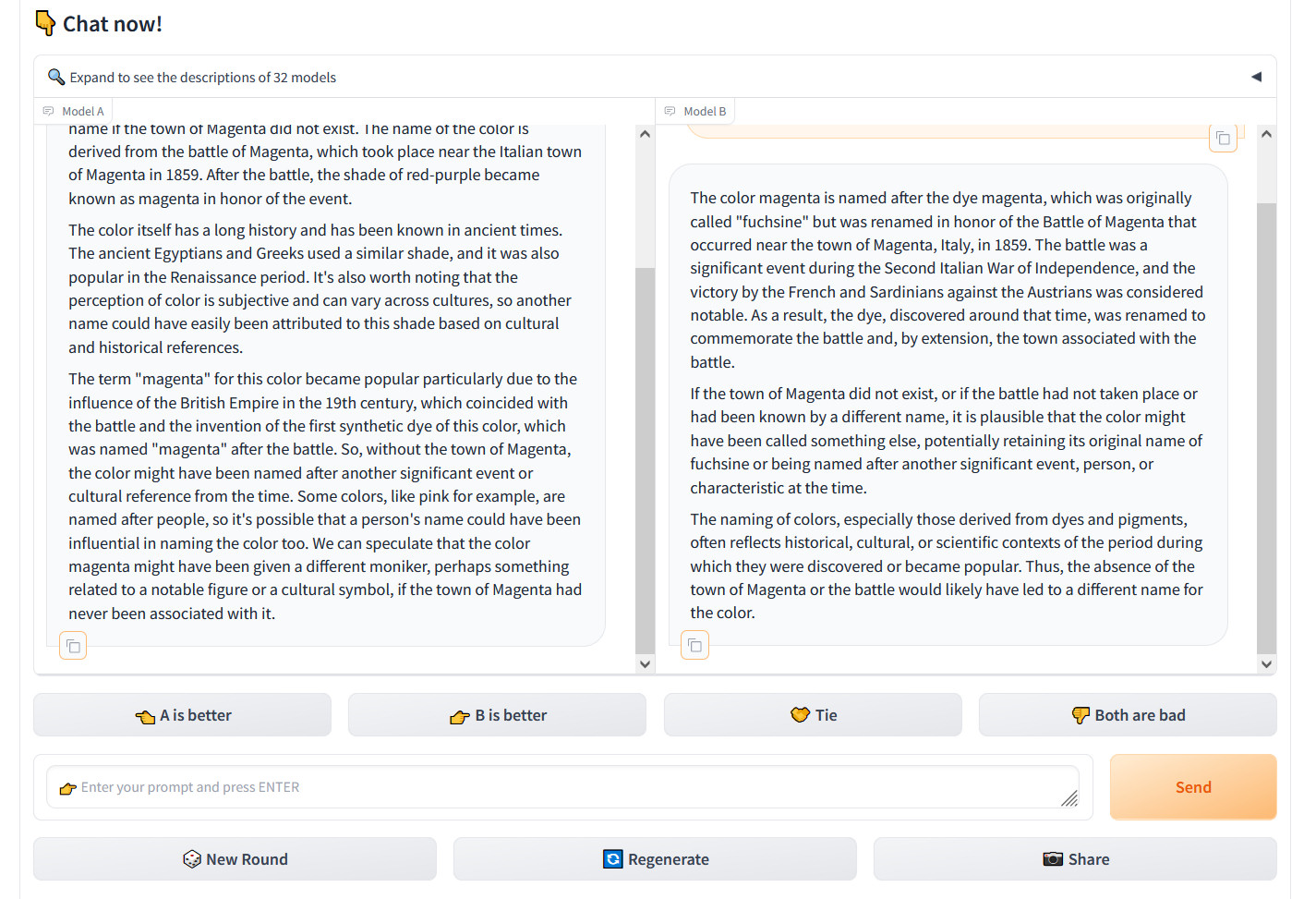
Enlarge / A screenshot of Chatbot Arena on March 27, 2024 showing the output of two random LLMs that have been asked, “Would the color be called ‘magenta’ if the town of Magenta didn’t exist?”
Benj Edwards
The “vibes” sentiment is common in the AI space, where numerical benchmarks that measure knowledge or test-taking ability are frequently cherry-picked by vendors to make their results look more favorable. “Just had a long coding session with Claude 3 opus and man does it absolutely crush gpt-4. I don’t think standard benchmarks do this model justice,” tweeted AI software developer Anton Bacaj on March 19.
Claude’s rise may give OpenAI pause, but as Willison mentioned, the GPT-4 family itself (although updated several times) is over a year old. Currently, the Arena lists four different versions of GPT-4, which represent incremental updates of the LLM that get frozen in time because each has a unique output style, and some developers using them with OpenAI’s API need consistency so their apps built on top of GPT-4’s outputs don’t break.
These include GPT-4-0314 (the “original” version of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved function calling support,” according to OpenAI), GPT-4-1106-preview (the launch version of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the latest GPT-4 Turbo model, intended to reduce cases of “laziness” from January 2024).
Still, even with four GPT-4 models on the leaderboard, Anthropic’s Claude 3 models have been creeping up the charts consistently since their release earlier this month. Claude 3’s success among AI assistant users already has some LLM users replacing ChatGPT in their daily workflow, potentially eating away at ChatGPT’s market share. On X, software developer Pietro Schirano wrote, “Honestly, the wildest thing about this whole Claude 3 > GPT-4 is how easy it is to just… switch??”
Google’s similarly capable Gemini Advanced has been gaining traction as well in the AI assistant space. That may put OpenAI on guard for now, but in the long run, the company is prepping new models. It is expected to release a major new successor to GPT-4 Turbo (whether named GPT-4.5 or GPT-5) sometime this year, possibly in the summer. It’s clear that the LLM space will be full of competition for the time being, which may make for more interesting shakeups on the Chatbot Arena leaderboard in the months and years to come.


