Building Metatron: State-of-the-Art Leads Forecasting using Transformers, Ensembling, and Meta-Learners
Metatron, the what and why
Lead generation is our principal way to monetize on our platform in the real estate industry. Accurate lead forecasts are paramount to helping guide Sales, Product, Data Science, and Finance to set the company up for success.
When you underestimate lead forecasts, money is left on the table because you have more lead volume you can sell. When you overestimate, you end up with under-fulfillment because you are selling more volume than is coming in. Furthermore, under-fulfillment decreases customer satisfaction, and there’s a higher likelihood of customer churn, which we vehemently want to avoid.
Previous state-of-the-art time-series models such as recurrent neural networks (RNNs) – Facebook’s Prophet – and Long-Short Term Memory (LSTM) models have worked well for us in the past. This time, we wanted to push beyond standard techniques and embark on a project that was adaptable enough to provide accurate forecasts in the face of challenges, for example, shifts from black swan events (COVID-19), rising interest rates, and market uncertainty.
Enter Metatron
To solve this problem, we created a stacked ensemble model that combines various modeling approaches and incorporates multiple state-of-the-art temporal fusion transformer (TFT)[1] models. TFT models are effective for modeling time-series data and can be fed multiple sequential time series directly and simultaneously. The TFT model uses the transformers you have heard about in large language models (LLMs) such as ChatGPT and applies the same techniques to Realtor.com’s lead data.
TFT is a formidable approach, which we further enhance by ensembling it with traditional models. We weight each model according to its recent historical performance, optimizing our combined forecasting power. Then, we use a meta-learner to build a final stacked ensemble model, which takes in the multiple modeling approaches and outputs a single prediction per zip code and product vertical. The ZIP code predictions are made monthly and predicted out 12 months into the future. We call this innovative and adaptable approach “Metatron.” Metratron helped us overcome many challenges in the current real estate climate and make accurate predictions in the face of uncertainty. It’s also helping the business drive revenue while increasing customer satisfaction.
This post delves further into our methodology and the various modeling approaches used to build Metatron.
How Did We Build Metatron?
Overview
To effectively manage the significant variation in lead volumes across ZIP codes, the ZIPs are categorized into deciles according to their lead volume. Lower-numbered deciles (1, 2, 3, etc.) include ZIP codes with higher lead counts, whereas higher-numbered deciles (7,8,9,10) consist of ZIPs with lower lead volumes. The low and high-volume deciles are trained separately, with deciles 1 through 9 forming one training group and the lowest-volume decile (10) forming the other. This approach allows for tailored-modeling strategies better suited to each decile group’s characteristics.
Note that we can only use decile training for models that allow passing in multiple time series. In contrast, the models we used from the Darts library work on single time series and will be referred to as local models from now on. Local models make predictions at individual ZIP code levels. We will discuss these in more detail in the following sections.
The model forecasts are output monthly, and the model training is updated monthly to ensure the most accurate predictions. Now, we will explore the traditional and various TFT models further.
Models
Local Models Using Darts
In Metatron, we leverage models from the Darts[2] library that utilize traditional and naive forecasting techniques. Each model is a local model trained on an individual time series for each ZIP code, creating a distinct model for each product and every ZIP code. Total models = # zip codes x # products, where each model has a single prediction.
These models include:
- Naive Drift: A model that constructs a straight line from the initial to the final data point in the training series and extends this trend into the future.
- Naive Mean: This model consistently forecasts the average value of the training series.
- Naive Moving Average: This model employs an autoregressive moving average (ARMA) approach with a specified sliding window parameter.
- Naive Seasonal: This naive model forecasts based on the value from K time steps prior. In our application, we use K=12, reflecting the assumption that the patterns observed in the previous 12 months will recur in the following 12 months.
Temporal Fusion Transformer
The other key piece of the puzzle in Metatron is the transformer-based model known as the TFT. The “Temporal” aspect of TFT highlights its focus on time-related or sequential data with inherent dependencies (each product and ZIP code’s monthly lead volume). “Fusion” signifies its capability to amalgamate information from various data sources. This can be historical time-varying features, which are only known up to the time of prediction (for example, the past lead volume of all product verticals), static or time-invariant features (for example, ZIP or latitude/longitude), and known future inputs (for example, months or holidays like Christmas day). “Transformer” denotes its basis in the Transformer architecture that allows it to learn longer-term dependencies [1] and is the same architecture as the basis for the current LLM revolution.
TFT is a global model that analyzes the relationships between various time series of ZIP codes collectively rather than individually. It utilizes a shared representation to uncover underlying patterns and trends across all series. By modeling the combined distribution, TFT can identify complex patterns and relationships that are difficult or nearly impossible for local models to extract, even if expertly designed.
In addition to being a global model, TFT enables simultaneous training and prediction of multiple targets. This means you can use a single model to predict not only across every zip code but also for every product – at once. Unlike local models, which require separate inputs for each product, you can input each product’s time series (Connections Plus, MarketVIP, Ready Connect Concierge, and Third Party) into a single model and obtain distinct forecasts for each product (multi-target).
We tried multi-target TFT models, which were predicted using a single model across all products, and single-target models, which independently predicted each product. The single-target models used the same data as the multi-target models (Connections Plus, MarketVIP, Ready Connect Concierge, and Third Party time-series data) but just had that single product’s predictions output for each model. There were tradeoffs between using a multi-target and single-target model from modeling, ease of implementation, and results standpoints.
Multi-target TFT Model vs. Single-target Model Tradeoffs
- Multi-target had only one set of tuned hyperparameters and one model to run during inference, simplifying the code and infrastructure required for training.
- Single-target allowed for a simpler optimization function and generally quicker training times but required more models with different optimal hyperparameters.
For both the multi-target model and single-target model, we trained on deciles 1-9 and decile 10 separately. Therefore, the multi-target had a total of 2 models equal to the number of decile groups, where each model has a prediction for each ZIP in that decile group across all the products simultaneously. The single-target model had a total of 8 models equal to the number of decile groups (2) times the number of products (4), where each model has a prediction at the product level for each ZIP in that decile group.
Model Ensembling
Weighted Ensemble on Recent Performance
Following the development of the TFT and naive models in our Metatron framework, we refined our forecasting accuracy through a targeted ensemble methodology. This approach involved weighting models based on their recent performance, specifically over the last three months, using Weighted Average Percentage Error (WAPE) evaluated at the decile level. We prioritized models with lower error rates and calculated the reciprocal of each model’s WAPE. These reciprocal values were normalized to determine each model’s proportional contribution to the ensemble. This ensured that weights were uniquely tailored to each decile.
Finally, we applied these weights to the predictions within each decile, multiplying each ZIP code’s predictions by the corresponding decile weight and summing the results to generate the final ensemble output. This was all computed for each product individually and not globally across all products. This methodology leverages the strengths of both global and local models and dynamically adjusts to the most recent data, optimizing prediction accuracy across our vast array of ZIP codes and products.
Introducing Metatron: Stacked Ensemble Model (Catboost – Meta-Learner)
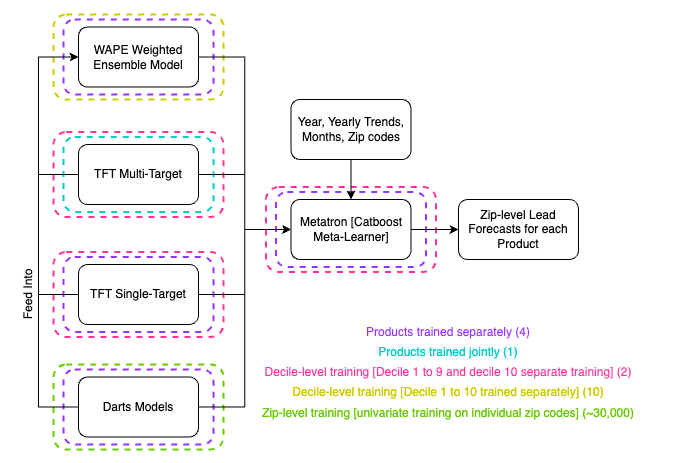
Now, we have all the necessary pieces to unveil the full power of Metatron, our CatBoost[3] meta-learner that combines all the efforts presented above. This model integrates predictions from global models (TFT models), local models (Darts models), and the decile-weighted ensemble model. It also incorporates additional time-related contextual data such as year, yearly trends, and cyclic time features. The diagram below illustrates how the final Metatron predictions are generated:
The base models feed into a WAPE-weighted ensemble model, and then all models, including the WAPE-weighted ensemble model, feed into Metatron, a Catboost meta-learner. Also, the diagram shows if the models were trained jointly or separately by product and trained at the zip-level or decile level. To get the total number of models in each block outputting predictions for each zip code and product, you need to multiply the two numbers in parentheses (x) of the dotted color boxes for that corresponding block. For example, TFT Single-target would be (4) x (2), so 8 total models giving predictions across all zip codes and products.
Furthermore, the meta-learner was trained differently for low and high-volume decile groups to optimize performance better:
- Mean Absolute Error (MAE) was used as the loss function for higher volume groups (deciles 1-9) due to its robustness for larger and non-zero biased datasets.
- Tweedie loss function was chosen for the lowest volume group (decile 10) to handle scenarios with high incidence of zeros effectively.
The meta-model outperforms all other models to effectively piece together accurate ZIP-level predictions across the various products. It does this by synthesizing insights from the various models and additional features given to the meta-model. This was the final piece of the modeling puzzle to get the desired adaptable state-of-the-art results.
Evaluation
We evaluated the performance of our models using several metrics, including total percentage error, the percentage of ZIP codes with errors within 20%, and WAPE. WAPE helps us evaluate how accurate each model is by measuring the size of errors in relation to actual values. It’s calculated simply by taking the total of all absolute errors between predicted and actual values, dividing that by the sum of all actual values, and then converting that number into a percentage.
This metric is particularly useful for comparing performance consistently across different ZIP codes and deciles, ensuring we understand which models perform best in which areas.
How Does It Perform?
When comparing model performance at both the ZIP code level and the aggregate decile level, Metatron, our Catboost stacked ensemble model, consistently stands out as the most accurate and reliable model.
ZIP Code Level Analysis:
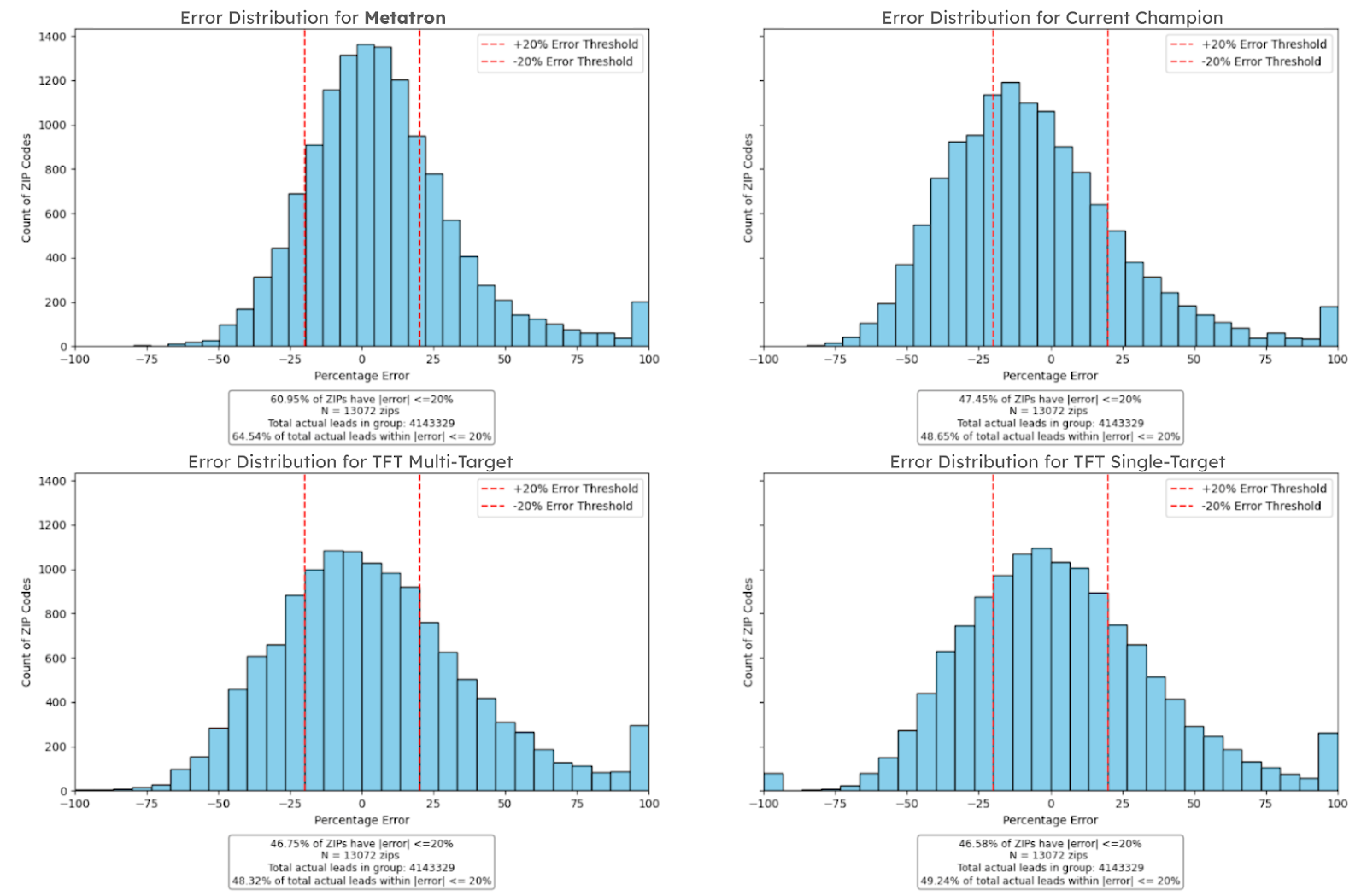
Metatron excels with 60.95% of ZIP codes within the ±20% error threshold, and it captures 64.54% of total actual leads within this range, as shown in the figure below. The Current Champion and TFT models have around 47% ZIP codes within the ±20% threshold. Therefore, the average percent relative accuracy increase with Metatron at the zip code level is 30%. This indicates Metatron’s superior prediction accuracy over the current champion or TFT models by themselves.
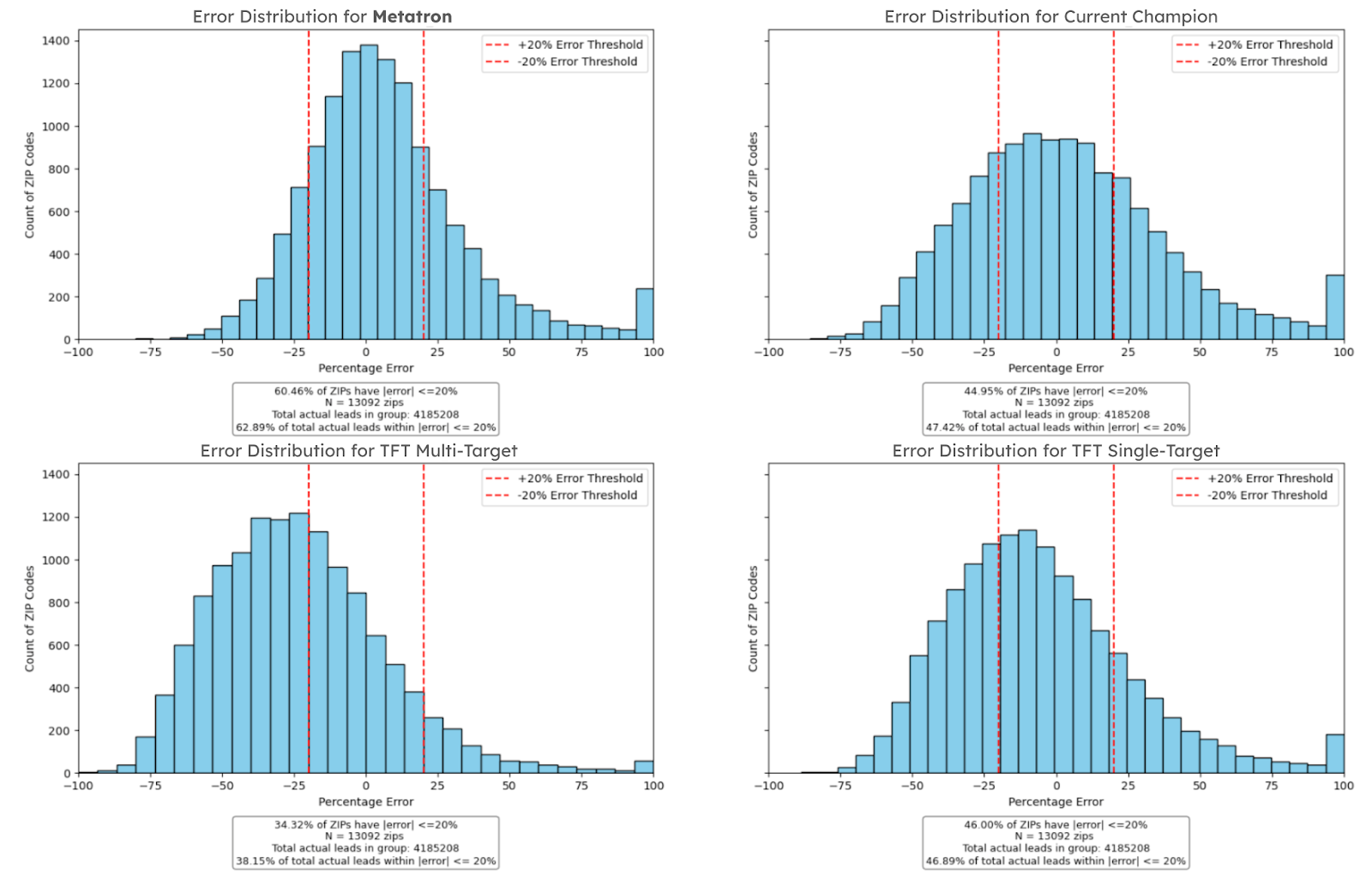
Furthermore, we see this increased accuracy stable over month-to-month predictions. The plot below shows the prediction for the month after the plot above. Metatron again excels, with 60.46% of ZIP codes within the ±20% error threshold and 62.89% of total actual leads within this range captured. For this month, one of the TFT models dropped to 34.32% of ZIP codes with the ±20% error threshold from 47%, highlighting the higher month-to-month volatility in individual models. Notably, this month’s average percent relative accuracy increase is 42%. Once again, Metatron provides vastly improved relative prediction accuracy, and this trend is expected to continue in future months not shown here.
Aggregate Decile Level Analysis
Metatron maintains the lowest WAPE across all deciles, highlighting its superior performance. The Naive Seasonal model shows the highest WAPE, indicating the lowest accuracy. Other models, including the Current Champion, TFT Multi-Target, TFT Single-Target, Naive Ensemble, and Decile Ensemble, consistently have higher WAPE values than Metatron.
Higher-volume ZIP codes (deciles 1 and 2, for example), which have better data distributions and less noise, benefit more from single-target models. In contrast, lower-volume ZIP codes, which are noisier and sparse (containing many zeros), benefit from the joint optimization across all product verticals provided by multi-target models. The plot below shows that the single-target model performs better in the lower deciles, and the multi-target model performs best in decile 10.
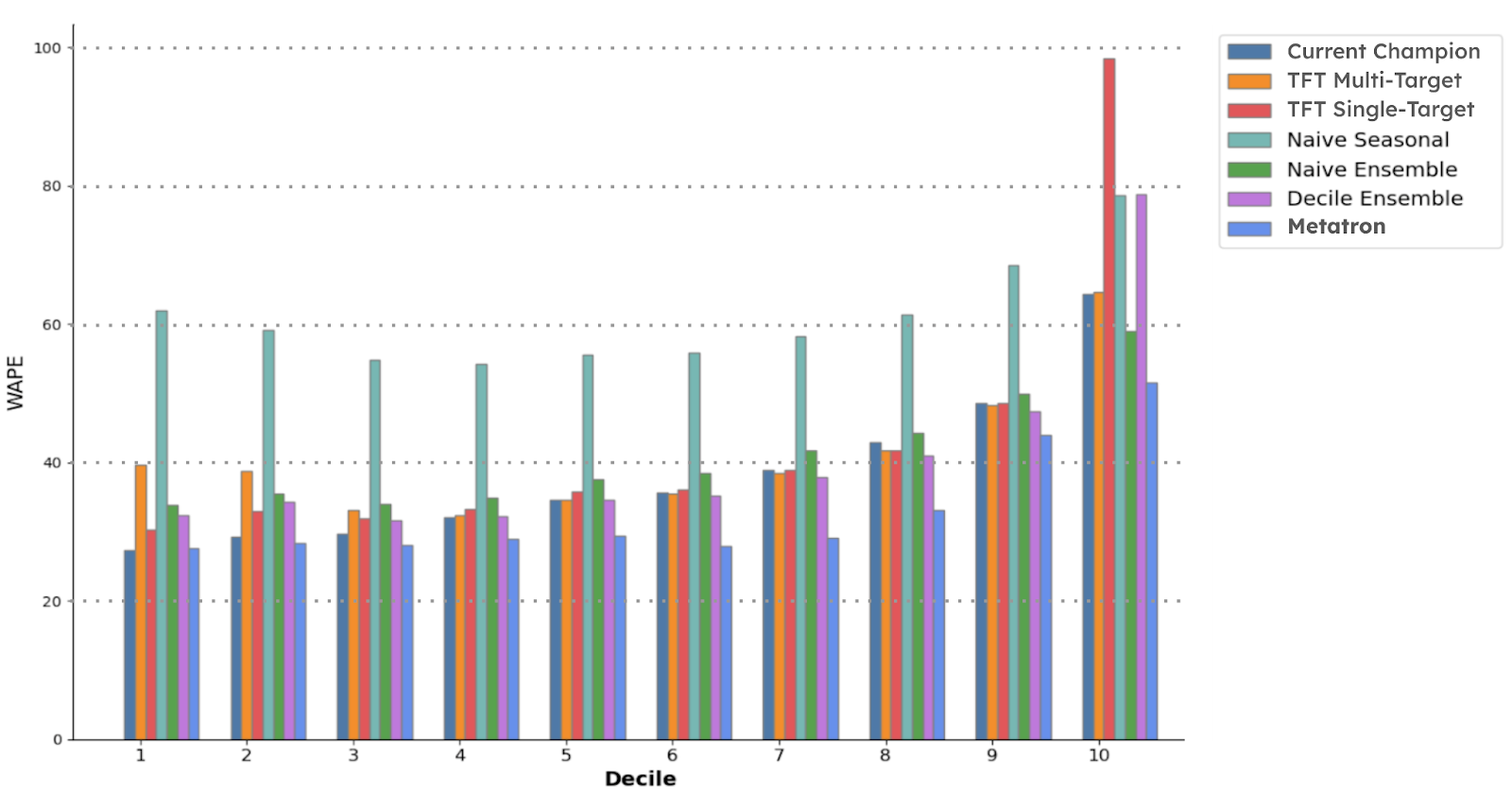
Overall Performance
Metatron stands out as the most reliable model and has demonstrated superior accuracy, minimizing the width of the error distribution at the ZIP code level and lowering WAPE at the decile level. This reinforces Metatron’s effectiveness in utilizing predictions from individual models to enhance the overall performance across all ZIPs. Similar results were observed across different forecasting periods, making it the preferred model and new champion. Long live Metatron!
Conclusion
Lead generation is paramount to a company’s success, particularly in the real estate industry. We embarked on a journey to get better and better at predicting future lead forecasts and developed a robust, state-of-the-art approach – Metatron – to generate lead forecasts. Metatron has a basis in modern transformer networks using TFT combined with many other modeling techniques, such as ensembling, meta-learning, and innate knowledge about how the real estate market works, to deliver accurate monthly forecasts that predict 12 months into the future.
Metatron enables greater revenue by not underpredicting lead volume, which can result in money left on the table for Sales. At the same time, we can delight customers by delivering on our promise and not selling too much lead volume in the market. This provides Realtor.com with more accurate lead forecasting abilities and a competitive edge despite market uncertainties.
Please contact Jeff Spencer or Siddharth Arora with any comments or questions. We are always interested in talking to others in the industry.
Ready to reach new heights at the forefront of digital real estate? Join us as we build a way home for everyone.
References
- Lim, Bryan, Sercan Ö. Arık, Nicolas Loeff, and Tomas Pfister. “Temporal fusion transformers for interpretable multi-horizon time series forecasting.” International Journal of Forecasting 37, no. 4 (2021): 1748-1764.
- Herzen, Julien, Francesco Lässig, Samuele Giuliano Piazzetta, Thomas Neuer, Léo Tafti, Guillaume Raille, Tomas Van Pottelbergh, et al. “Darts: User-friendly modern machine learning for time series.” Journal of Machine Learning Research 23, no. 124 (2022): 1-6.
- Dorogush, Anna Veronika, Vasily Ershov, and Andrey Gulin. “CatBoost: gradient boosting with categorical features support.” arXiv preprint arXiv:1810.11363 (2018).



